2021 will always be remembered as the year that world took Ransomware seriously. This is because reported ransomware attacks doubled from the previous year, 2020; these attacks cost companies an estimated $2 billion total in both recovery and in some cases paid ransom. Â
With the shift to containers, this has only complicated matters for companies. stackArmor has led multiple customers leveraging containers through FISMA, FedRAMP, CMMC, and DoD SRG audits. Here are the top 10 things customers should be focused on to protect against not only Ransomware, but all intrusions.
- Proper OS security on worker nodes
-
- Install Host-based security software – file integrity monitoring, anti-virus, and application control.
- Harden to an acceptable benchmark like DoD STIG or CIS Benchmarks.
- Scan for vulnerabilities on the host regularly
Ransomware is at the end of the day, just a type of malware – it just gained popularity in recent years due to the rise of cryptocurrency and the possibility of anonymous payments. So, it makes sense that the first lines of defense to protecting containerized applications from malware is proper hardening and a solid HBSS with frequent signature updates. One common point of confusion is whether the containers themselves need AV etc. The answer is no – containers use a union mount file system, so the containerized apps will inherit the protections applied to the hosts. It is also important to leverage agent-based vulnerability scanners (rather than remote scanners that leverage SSH or SMB protocols) as this allows you to completely close remote access to your worker nodes. **
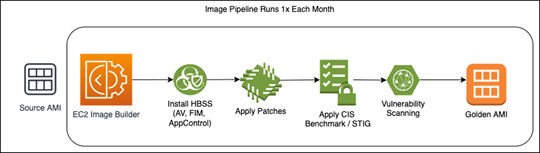
Also, it is recommended that companies leverage an immutable deployment strategy for updating their worker nodes – do not patch and update in place! To accelerate security, it is recommended that an Image Pipeline is created to automate the creation of your golden worker node AMI monthly. AWS EC2 Image Builder is a perfect candidate for this, as it allows you to write custom recipes using SSM and created a schedule for the creation of your golden AMI; this new AMI is then pushed monthly to your worker nodes. EKS has built in features to accelerate updates of worker nodes which includes the cordoning of nodes, re-scheduling of pods etc.
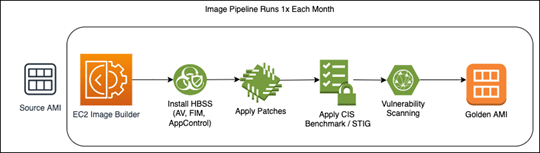
** – Access to hosts can be still delegated using AWS Sessions Manager. Sessions Manager does not require any open inbound ports and can integrate with external IDPs to enforce corporate access policies such as strong MFA and device posture checks.
2. Deploy HIDS such as Falco.
While most host-based security software these days includes Application Control – which only allows desired applications to run, it may not be enough. Depending how the solution is implemented – hash-based, heuristic-based, it can be often problematic for many workloads, especially those that are container-based. This why it is important to implement an additional host-based intrusion detection system (HIDS) such as Falco.Â
Falco can be deployed as a binary on the worker node itself (in which case it would be included in the image pipeline above); however, it also supports deployment as DaemonSet, which integrates seamlessly with autoscaling Kubernetes workloads. If using a DaemonSet, there is no need to pre-bake Falco into the worker node AMI.
Falco uses either kernel modules or the newer eBPF to monitor every process’s interaction with the host’s kernel. With its fully extensible DSL, you can write custom rules to alert on any suspicious behavior.Â
Here is an example rule for notifying for a shell is opened inside of a container.
| – rule: shell_in_container  desc: notice shell activity within a container  condition: evt.type = execve and evt.dir=< and container.id != host and proc.name = bash  output: shell in a container (user=%user.name container_id=%container.id container_name=%container.name shell=%proc.name parent=%proc.pname cmdline=%proc.cmdline)  priority: WARNING |
Here is an example of an alert when a process writes to sensitive system directories.
| – macro: open_write  condition: >    (evt.type=open or evt.type=openat) and    fd.typechar=’f’ and    (evt.arg.flags contains O_WRONLY or    evt.arg.flags contains O_RDWR or    evt.arg.flags contains O_CREAT or    evt.arg.flags contains O_TRUNC)  – macro: package_mgmt_binaries  condition: proc.name in (dpkg, dpkg-preconfigu, rpm, rpmkey, yum)  – macro: bin_dir  condition: fd.directory in (/bin, /sbin, /usr/bin, /usr/sbin)  – rule: write_binary_dir  desc: an attempt to write to any file below a set of binary directories  condition: evt.dir = < and open_write and not proc.name in (package_mgmt_binaries) and bin_dir  output: “File below a known binary directory opened for writing (user=%user.name command=%proc.cmdline file=%fd.name)”  priority: WARNING |
Falco supports integration with AWS CloudWatch Logs and Security Hub for proper tracking and processing of detected anomalies.
3. Control egress traffic flow.
Ransomware only gets into a network because it was either downloaded from a malicious location or uploaded by a malicious user. To protect against malicious downloads, controlling egress traffic is essential. Some companies may use egress gateways in a service mesh (like Istio) to craft policies to external services. However, that is insufficient – they only apply egress policies to containers that are part of the service mesh; any container or process outside of the mesh would not be respect the egress gateway policies. In EKS, egress traffic policies can be controlled in 3 ways:
Egress to internet – In today’s cloud-first world, truly air-gapped systems are becoming increasingly rare. At some point, your system will need to download a patch, an anti-virus update, a container image etc. from the internet. It is important to use firewall to control the flow of traffic between your EKS cluster and the internet. AWS Network Firewall is managed firewall that can provide protection against malicious domains used to host malware. It provides protection using the following:

- Stateless Rules – Used to limit which ports and protocols are allowed out to internet – typically: 80/TCP (HTTP), 443/TCP (HTTPS), 123/UDP (NTP), 53/UDP (DNS), 53/TCP (DNS).  Malware can be hosted on non-traditional ports and protocols not typically used over internet like 389/TCP (LDAP). The infamous Log4Shell Vulnerability was famously exploited using this method.
   b. Stateful Rules – Can be used to control TLS and HTTP traffic to remote domains. By inspecting the        SNI extension of the TLS Client Hello (or the host header in un-encrypted HTTP), the firewall can         block egress traffic to external domains. This can be done either by using allow lists or deny lists.
          (i) Managed Rule Groups AWS also provides managed rule groups that can be used as                    deny lists to malicious domains. Here are a few managed rule groups relevant to                        ransomwware.         Â
 For a full list, please visit: https://docs.aws.amazon.com/network-firewall/latest/developerguide/aws-managed-rule-groups-list.html
- AbusedLegitBotNetCommandAndControlDomainsActionOrder
- MalwareDomainsActionOrder
AbusedLegitMalwareDomainsActionOrderBotNetCommandAndControlDomainsActionOrderThreatSignaturesMalware
Access to AWS Services –While AWS does monitor accounts for abuse, it is possible that ransomware packages could be hosted in AWS services, particularly S3. When an application requires access to AWS services, adding a VPC endpoint with a strict endpoint policy can add a layer of protection and protect workloads from accessing unapproved AWS services and ultimately ransomware.

Diagram showing ways to protect access to s3 based resources
DNS Lookups – DNS is one of the fundamental protocols of the internet – there’s a reason why every engineer and administrator has shouted “IT’S ALWAYS DNS†at some point. This has led to DNS becoming an interesting attack vector for hackers. They can register a malicious domain – e.g., ransomware123.com, so all DNS queries for that domain are forwarded to their name servers. Any information that is included as a “subdomain†in a DNS query can be logged by the attacker. This can be a vector for data exfiltration, Command and Control and more. Data exfiltration is not “traditional†ransomware, but if sensitive data is leaked via this method, it could certainly be used as leverage to ransom an organization. The protection against this vector is called DNS Sink holing and AWS Route 53 Resolver DNS Firewall fits the bill. Sink holing allows you to inspect DNS queries and evaluate if it is a malicious domain; if it is malicious, the DNS Sink hole returns a dummy response to the DNS query, so the query is never forwarded to the malicious name servers. DNS Firewalls allows you to create specific allow lists, deny lists, or leverage AWS Managed lists for known malicious domains identified by AWS.

Diagram showing implementation of security protections for DNS lookups Â
Ransomware can be deployed as a container and anyone with access to the Control plane of your cluster can potentially deploy ransomware (wittingly or unwittingly).
Controlling access to authenticated users using the aws-auth ConfigMap in Kubernetes is important but so is controlling network access to the control plane itself. As is standard best practice with AWS access, avoid using AWS IAM Users for accessing the control plane – rely on IAM roles which can be shared amongst several users. A recent study found that approximately 380k different Kubernetes clusters have their Kubernetes API – and thus the control plane – exposed to the internet. While the API servers may still require authenticated access, it can easily be mitigated by limiting which public IPs can access the API server; or even better don’t expose it to internet at all and require a Client VPN – after all, credentials can be leaked or stolen.Â
 5. Least privilege in containers.
One of the more common ways ransomware will get introduced to a Kubernetes cluster is via one of the containers in the cluster. Therefore, it is important to implement proper runtime security on the containers themselves. By limiting the privileges of your containers your limit their ability to be used maliciously. Some common options for implementing container runtime security:
- Read-only root file system.
- Run container as a user with limited access to host.
- Deny privileged containers (unless specifically required) – using Admission Controllers such as OPA Gatekeeper.
- Restrict Linux kernel Capabilities – such as NET_ADMIN and SYS_CHROOT.
- Restrict hostPath volume mounts to non-sensitive directories on host.
- Restrict kernel access using AppArmor or SecComp profiles.
- Leverage AWS IRSA for access to AWS API to prevent relying on an overly permissive EC2 Instance Profile.
 6. Network segmentation.
Proper network segmentation of your workloads can go a long way to stopping the spread of ransomware if you do get infected. One common way to properly segment your cluster is using pod placement strategies such as Taints, Tolerations, NodeAffinity, and NodeAntiAffinity.  This will help schedule pods on unique worker nodes so if one service is compromised, it can prevent it from leaking into other services. This is not to say each service should get its own set of worker nodes; it’s important to understand your application’s architecture and how the microservice interact with other while designing these requirements. In additional to pod placement strategies, utilizing NetworkPolicies to control inter-service communication (NetworkPolicies are kind of like AWS Security Groups for Kubernetes – though you can now use Security Groups with EKS!) It’s important to note that the default AWS VPC CNI does not support NetworkPolicies out of the box. You must migrate to either a different CNI such as Cilium, or deploy the Calico Daemonset.
 7. Centralized Log Aggregation Warehouse and SIEM Integration.
Log aggregation and correlation from multiple log sources are essentially for determining if you have been compromised in a timely fashion. AWS does support shipping container logs to CloudWatch using FluentBit (or you can send them to corporate SIEM such as Splunk). By integrating with a SIEM or CloudWatch you can create automation to quickly terminate pods of entire worker nodes if they are determined to be compromised. This is why HIDS like Falco are essential and should be deeply integrated with your logging solution.
 8. Backup and recovery strategy.
Murphy’s law dictates that is not a matter of if you will be infected by ransomware but when.  This is why it is important for you to be backing up your data as often as financially possible. If you are infected, the easiest recourse is most likely a restore of your latest “clean†backup. If you are using EBS, EFS, RDS, S3, DynamoDB, FSx, DocumentDB, Neptune as persistent data stores for your EKS cluster you can easily automate your backups using AWS Backup. This will allow you to easily define RPOs for all scenarios not just ransomware, but also AZ and regional failures. This also integrated with AWS Backup Audit Manager so you can monitor the status and breadth of your backup jobs on a regular basis.
However, backups are only one side of this scenario – the restore is just as important! It is important to test your backups and perform full restores on a regular basis. There is no other way for you to determine if your backups are truly valid. They will also help you improve your process to minimize the RTO. Here is a great blog from AWS on how to determinte RTO and RPO for your organization.
 9. Scan container images regularly.
The beginning of all container security should start with scanning your container images on regular basis. Vulnerable packages can get introduced and exploited at any time, so it is important to scan during the build phase but also properly inventory what images are deployed in your environment. Here is a blog we wrote that breaks down proper container scanning policies – though it is written with regards to federal environments, the policies hold true for any organization.
 10. Harden your privileged users
The most vulnerable portion of any system is the administrators and engineers behind the scenes and it also the most crucial – they have the privileged access into your cluster. Therefore, it is important to require cyber security training for all employees on a regular basis. Properly securing your team’s workstations and teaching them to identify the latest social engineering methods is often the last line of defense.
Written By
Matthew P. Venne, stackArmor, Sr. Solutions Director
Matt provides technical and architectural leadership on
complex segmentation, encryption and Kubernetes deployment services meeting
NIST requirements.
Â
Â