Written by Matt Venne, Managing Director, stackArmor
The advent of artificial intelligence (AI) is transforming practically every corner of our world. Concurrently, the need for MLSecOps platforms has become fundamental in ensuring the security of AI systems. Traditional security models often fall short in addressing the unique vulnerabilities inherent in AI systems. The integration of AI into the software development lifecycle (SDLC) is pivotal in fortifying the security frameworks of organizations leveraging AI technologies. Additionally, the introduction of AI Security Posture Management and scanning for AI-specific vulnerabilities play crucial roles. Implementing an LLM Firewall further enhances these security measures. These measures are essential for ensuring the robust protection of systems that utilize AI.
Uncharted Waters: Unique Attack Vectors in AI Systems
AI systems introduce a set of unique attack vectors that traditional security models are not equipped to handle. Unlike conventional software, AI systems can be susceptible to data poisoning, model inversion attacks, and adversarial machine learning. These attack vectors exploit the inherent characteristics of AI models, such as their reliance on data and the complexity of their decision-making processes. For example, data poisoning attacks manipulate the training data to compromise the model’s integrity, leading to skewed or malicious outcomes. Similarly, adversarial machine learning leverages subtle, intentional inputs to deceive AI models into making erroneous predictions or classifications.
Therefore, understanding and mitigating these unique attack vectors necessitate a specialized approach. To address these challenges, MLSecOps platforms provide tools and methodologies specifically tailored to the nuances of AI security. Consequently, these platforms enable organizations to proactively identify, assess, and mitigate the risks associated with their AI systems, ensuring their integrity and trustworthiness.
Bridging Worlds: Inclusion of Data Scientists in SDLC
The inclusion of data scientists into the standard Software Development Life Cycle (SDLC) introduces a paradigm shift. This shift changes the skill sets required by traditional cybersecurity staff. Traditionally focused on network vulnerabilities, malware, and system exploits, cybersecurity professionals must now broaden their expertise. They need to understand the nuanced complexities of AI and machine learning models. This paradigm shift is similar to the shift that occurred as containerization became more mainstream. This new terrain encompasses data integrity, model robustness, and AI-specific threat vectors, such as the ones covered above.
Cybersecurity personnel need to collaborate closely with data scientists, understanding the lifecycle of AI models from conception to deployment. This collaboration requires a foundational knowledge of how AI models are trained, validated, and integrated into applications, as well as an understanding of the data these models interact with. Additionally, cybersecurity teams must be versed in new tools and methodologies specific to AI security.
By acquiring these additional skill sets, cybersecurity professionals can better identify and mitigate threats specific to AI systems, ensuring a holistic security approach that encompasses both traditional IT infrastructure and the emerging domain of AI technologies. This evolution in skills not only enhances the security of AI systems but also supports a more integrated and resilient SDLC in the age of AI.
AI Security Posture Management: A Proactive Stance
The dynamic nature of AI systems, with continuous learning and adaptation, necessitates a robust AI Security Posture Management solution. This solution provides a comprehensive overview of all AI models and pipelines in an organization’s environment, along with their associated security profiles. It enables organizations to track the security status of their AI assets in real-time, identify potential vulnerabilities, and respond to emerging threats promptly.
AI Security Posture Management goes beyond traditional security monitoring by providing insights into the unique aspects of AI security. It considers the lineage of data, the integrity of models, and the security of the deployment environment. By offering a centralized view of AI security, organizations can ensure that their AI systems remain secure, compliant, and aligned with their security policies.
Scanning for AI-Specific Vulnerabilities: Beyond Conventional Measures
AI systems require a new breed of vulnerability scanners that can detect issues beyond the scope of traditional tools. Traditional vulnerability and malware scanners are adept at identifying known threats in software systems but may not detect vulnerabilities unique to ML models. These unique vulnerabilities include model serialization attacks, where malicious code can be hidden in the layers of ML models and executed without user knowledge every time a model is invoked. Scanning ML Models for these unique vulnerabilities is crucial for securing AI systems. These scanners must understand the architecture of AI models and the nature of the data they process. They must also comprehend the specific ways in which these models can be compromised. By incorporating AI-specific scanners into the security toolkit, organizations can ensure that their AI systems are secure against traditional threats. Additionally, these systems will be resilient against attacks targeting their unique vulnerabilities.
LLM Firewall: A Shield for Content Moderation
The predominant approach to AI implementation globally is characterized not by the development or refinement of models in-house. Instead, it relies on the utilization of pre-existing, hosted Large Language Models (LLMs) such as OpenAI, AWS BedRock, and Google Gemini. While these LLMs undergo some degree of adversarial training, their training contexts remain broad. They may not counteract the unique threats specific organizations face. This is where content moderation becomes indispensable.
Content moderation is an essential component in fortifying Large Language Models (LLMs). It proactively addresses a range of intrinsic risks, including prompt injection, insecure output handling, sensitive data disclosure, and overreliance on model outputs. This process is not merely about filtering inappropriate content but ensuring that the LLM’s outputs are aligned with the specific security, ethical, and operational standards of an organization. It acts as a critical layer of defense, customizing the LLM’s general capabilities to the nuanced requirements and threat landscapes of individual organizations. This enhances the overall security and reliability of AI deployments.
Here’s how content moderation plays a pivotal role in mitigating these risks:
- Prompt Injection: This occurs when malicious users craft inputs designed to manipulate the model into generating harmful or unintended outputs. By employing content moderation, organizations can detect and neutralize such inputs before they affect the model’s behavior. This preventive measure ensures that attackers do not exploit LLMs to produce outputs used for misinformation, manipulation, or perpetuating harmful biases.
- Insecure Output Handling: Any LLM-generated output has the potential to cause damage. This damage can occur through malfeasance or hallucination. This can be exacerbated when the LLM is ingesting or producing data meant for programmatic consumption downstream, such as XML, HTML, or JSON. By employing content moderation, organizations can protect against output serialization attacks. These attacks occur when attackers embed malicious content in the LLM responses.
- Sensitive data disclosure: Large Language Models (LLMs) possess the inherent risk of unintentionally disclosing confidential information within their responses, thereby facilitating unauthorized data access. Content moderation serves as a proactive barrier, meticulously scrutinizing and filtering LLM outputs to prevent the exposure of sensitive data. This aspect is particularly critical in systems that utilize Retrieval Augmented Generation (RAG).
- Over-reliance on LLM Outputs: Users might over-rely on the information provided by LLMs, treating it as factually accurate or infallible. Content moderation helps mitigate this risk by ensuring that outputs are not only appropriate but also flagged or contextualized when necessary. This measure safeguards against LLMs generating responses that could tarnish an organization’s brand reputation.
In essence, content moderation serves as a safeguard, ensuring that LLMs operate within the bounds of safety, ethics, and user trust. It is a key component in the broader context of AI governance. This ensures that the deployment of these powerful models aligns with societal values and standards.
An LLM Firewall acts as a protective layer that proxies connections from users to the backend LLM. It scrutinizes and filters inputs and outputs to prevent the dissemination of harmful or inappropriate content. This firewall is essential for maintaining the integrity and safety of platforms utilizing LLMs. It ensures that they align with ethical standards and regulatory requirements. It provides a mechanism to enforce content policies, prevent exploitation of the model, and safeguard users from malicious or biased outputs.
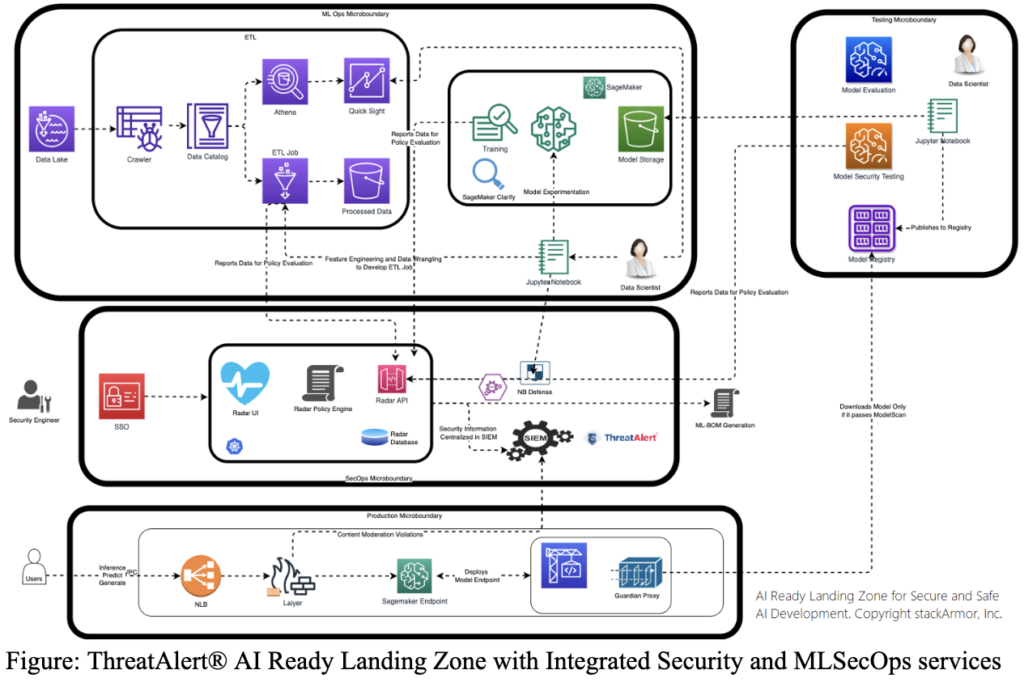
Secure by Design AI Ready Landing Zone
The cloud, security, and compliance experts at stackArmor have developed a reference implementation. This implementation rapidly enables secure and safe AI development. This implementation utilizes MLSecOps to achieve its objectives. As more AI-enabled systems get adopted by organizations in regulated markets, it is important to ensure that safety, security, and compliance requirements are met. These measures are crucial for the reliable and ethical implementation of AI technologies. Address these requirements right from the initial design of the environment. The use of microboundaries, continuous monitoring and additional AI assurance services can help reduce the friction to developing and deploying secure and safe AI. The stackArmor AI Ready Landing Zone architecture is designed to be an isolated boundary with strong data ingress and egress controls and ideal for enabling sovereign digital platforms. The stackArmor AI Ready Landing Zone is enabled by the AWS Landing Zone Accelerator.
Conclusion
The advent of AI has brought about a paradigm shift in technology, necessitating a reevaluation of our security practices. MLSecOps platforms offer a comprehensive suite of tools and methodologies tailored to the unique challenges of AI security. By addressing the specific vulnerabilities of AI systems, organizations can safeguard their AI investments and ensure the trustworthiness of their AI-driven initiatives. Integrating data scientists into the SDLC and implementing AI Security Posture Management are crucial steps in this process. Scanning for AI-specific vulnerabilities and establishing an LLM Firewall further enhance the security of AI technologies. Embracing these practices is not just a proactive measure for risk mitigation; it is a strategic imperative to foster innovation, maintain competitive edge, and build enduring trust in AI technologies.


