Federal Agencies are rapidly deploying and utilization AI/ML technologies to further the mission. This blog attempts to understand the types of AI/ML systems being used by agencies and how best to develop relevant guardrails. OMB’s M-14-10 memo outlines specific requirements that must be met for ensuring Responsible AI deployments.
Responsible AI Directives from OMB
As part of its guidance to agencies to ensure Responsible AI use as recommended by the NIST AI RMF to maintain AI system and use case inventories, OMB’s guidance M-24-10 is prescriptive, and direct. Its states, in Sections 3-a-iv and 3-a-v:
- AI Use Case Inventories. Each agency (except for the Department of Defense and the Intelligence Community) must individually inventory each of its AI use cases at least annually, submit the inventory to OMB, and post a public version on the agency’s website. OMB will issue detailed instructions for the inventory and its scope through its Integrated Data Collection process or an OMB-designated successor process. Beginning with the use case inventory for 2024, agencies will be required, as applicable, to identify which use cases are safety-impacting and rights-impacting AI and report additional detail on the risks—including risks of inequitable outcomes—that such uses pose and how agencies are managing those risks.
- Reporting on AI Use Cases Not Subject to Inventory. Some AI use cases are not required to be individually inventoried, such as those in the Department of Defense or those whose sharing would be inconsistent with applicable law and governmentwide policy. On an annual basis, agencies must still report and release aggregate metrics about such use cases that are otherwise within the scope of this memorandum, the number of such cases that impact rights and safety, and their compliance with the practices of Section 5(c) of this memorandum. OMB will issue detailed instructions for this reporting through its Integrated Data Collection process or an OMB-designated successor process.
AI Usage in Federal Agencies
If you haven’t already been to it, the US Federal Government’s website on AI, www.AI.gov, is an informative resource. Its purpose is to act as a central hub for information about the United States government’s efforts, policies and resources related to artificial intelligence.
On that website, the US government has published the first ever government AI use case inventory, available here: https://ai.gov/ai-use-cases/
The data is available as a CSV file for downloading – as of now there isn’t an online, interactive way to review and analyze the data. Which is just as well, because we were able to pull the downloadable CSV through some hoops to review the data in it and provide an analysis here.
The specific file that we downloaded is included in this blog post – as of 1st May 2024 this is the data that was available at AI.gov. The website may have a new version of the data at any point in the future, and it would be useful to compare and contrast them in the future.
Usage by Agency
The first question we believe most people would have is “where in the government are we using AI?”
This is what we can see:
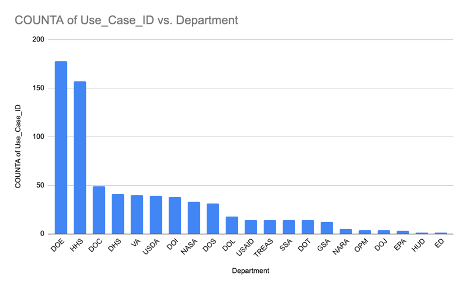
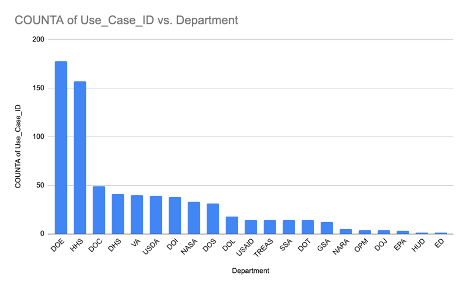
The top ten agencies with reported AI use cases include Department of Energy (DOE), Health and Human Services (HHS), Department of Commerce, Homeland Security, Veterans Affairs, USDA and a number of other agencies including Interior and NASA.
Lifecycle Status of AI/ML Initiatives
Understanding the state of the AI/ML initiatives is helpful in understanding the direction and potential future requirements. The AI use case inventory had 25 different statuses. Therefore it was hard to get a handle on what was the maturity level of the projects. We standardized the data into three broad buckets – where the AI/ML was either a pilot or proof of concept (POC), where the AI/ML system was in its development phase, and where the AI/ML system was now operational.
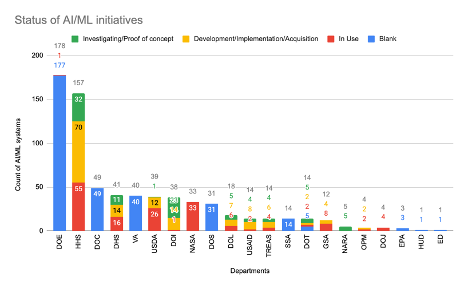
After standardization, we still had missing data – several agencies did not have any kind of project status such as DOE, which was missing the status field in the data download (CSV).
First, we looked at the agencies that had provided information about the status their AI/ML initiatives were in. There is a good mix of projects that were being initiated, vs projects that were now live and in use.
The outlier in this was the National Aeronautics and Space Administration (NASA). They had 33 projects, and all were live and in use. But they had no further projects in the pipeline for ideation, nor did they have any AI/ML initiatives that were currently “in-flight”. Given the complexity of the projects that they did have live, it seems unlikely that they have nothing else in progress. We’re going to chalk this down to either insufficient data, or a reporting process that only reports completed and live initiatives.
There is a great significance to this field – Development_Status – and to knowing what stage an agency’s AI/ML initiatives are in. The Whitehouse is prioritizing employment growth in the area of AI (https://ai.gov/apply/). Information about an agency’s initiatives in AI is of relevance to the HR departments of the agencies themselves. Pilot projects and POCs will give rise to development efforts where scientists, product managers and engineers will be required for eventual production deployments. Projects in flight will eventually go live and have a need for DevSecOps, training and infrastructure outlays. Agency administrators, CIOs would benefit from knowing the expected budget outlays for future years for this growth area. They would also want to have their sights on the efficiency gains that are expected to ensue from automation of tasks that were previously not automatable.
Given these benefits to having better insights, we felt that further analysis of the status of the initiatives was warranted and would be a productive exercise. And we wanted to look at the initiatives where there was no direct data on what their status was.
To perform this analysis, we asked Anthropic’s Claude 3 Opus to review the CSV file and try to ascertain the development status for every initiative that was blank by looking at the existing data. The CSV provided by AI.gov had a summary field with detailed descriptions for each of the projects that had a blank development status (which by itself is an observation on inventory quality), by looking at the Summary column that has a description of the work being done for that project. From that, Claude was able to infer the project statuses of the remaining 355 projects. The resulting graph is shown below.
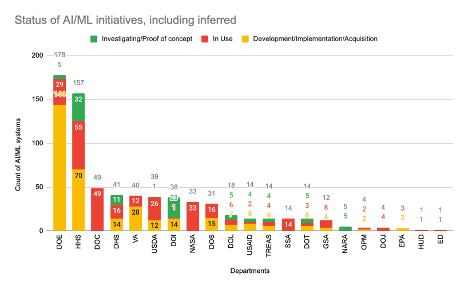
From this we can see that all the agencies that we have inferred information about have a reasonable mix of initiatives in the POC stage, in development and in use. The outlier in this case is the Department of Commerce, and all their initiatives are currently marked as in-use. We took a second manual pass over the data, and read the summaries ourselves to establish whether Claude’s inferences were correct and that all of the DOC’s AI/ML initiatives were live, and there were no other statuses – we believe that Claude’s inferences were correct, if one were to solely go by the Summary description that the DOC provided. Again, the takeaway here should be that the DOC, like NASA, has only provided information about AI/ML initiatives that are live, and nothing about what is currently in the pipeline and being worked on.
AI/ML Techniques and Approaches used across agencies
We also wanted to take a look at the approaches that were being used in AI/ML initiatives across US government agencies, and this too required some level of cleansing on the provided data. We faced three major challenges. The first challenge was that there isn’t an agreed upon taxonomy of classification for AI and ML approaches, therefore there isn’t a standard way of comparing the qualitative aspects of work being done in one agency vs another. The second challenge was that many projects and initiatives used multiple approaches, and the format of the data provided didn’t lend itself to separating those out (but we did make the effort to do so). The third challenge was that information on techniques was missing for the majority (395 out of 710) of the projects. We again used the summary field to determine what the techniques might be.
The most common technique mentioned (in over 100 projects) in the CSV is “machine learning” – which by itself is too broad to convey much meaningful information.
In specifically named techniques, the most common one by far was Natural Language Processing (NLP). Agencies as diverse as the DHS, USDA and the DOE are relying on NLP approaches for a variety of tasks.
A close second is Computer Vision/Image Analysis for object recognition and image segmentation/classification. Several of these are combined with autonomous systems and robotics with the intent to create observation and measurement platforms that operate without human intervention, e.g. in the field of weather measurements and wildlife/ocean conservation efforts.
A third category of projects is classification and anomaly detection. Federal government agencies routinely handle large volumes of data, most of it unstructured. Agency teams have recognized the opportunity that machine learning presents for parsing that data efficiently, and improving the effectiveness of government services, e.g. both the USCIS and DOL are using this technique to help streamline and improve efficiencies in their case management systems.
On the other hand, generative AI (GenAI) techniques and approaches were few and far between. There is one mention of the term “LLM”, one mention of ChatGPT and three mentions of Generative Adversarial Networks (GANs). Our assessment is that this is more an artifact of data lag rather than an indication that government agencies are not taking advantage of GenAI. In the next iteration of this inventory, we expect to see GenAI being used broadly across the government.
Looking at Use Cases
Next we took a high level view of how some key agencies are using AI/ML. While these are early days yet, it is possible to pick up insights.
The Department of Homeland Security (DHS) is using AI/machine across Customs and Border Protection (CBP), Cybersecurity and Infrastructure Security Agency (CISA), and Immigration and Customs Enforcement (ICE). Common use cases include:
- Object detection/image recognition for security purposes (e.g. detecting anomalies in X-ray images, vehicle detection)
- Natural language processing for analyzing unstructured data (e.g. processing text from docket comments, case reports)
The Department of Health and Human Services (HHS) has several efforts around using natural language processing and machine learning for healthcare and biomedical applications, led by agencies like:
- Centers for Disease Control (CDC) – Detecting health conditions from medical images, analyzing social media data.
- Food and Drug Administration (FDA) – Adverse event analysis, review of drug applications.
- National Institutes of Health (NIH) – Predictive models for disease progression, mining scientific literature
The Department of Veterans Affairs (VA) is applying AI for:
- Analyzing medical records/data for risk prediction (e.g. suicide risk, disease progression)
- Computer-aided detection/diagnosis from medical images and sensor data
- Clinical decision support systems
A notable VA project is “Predictor profiles of opioid use disorder and overdose” which uses machine learning models to evaluate risk factors.
Other Departments like USDA, DOT, EPA are utilizing AI/ML techniques like computer vision, natural language processing and predictive modeling:
- Crop/vegetation mapping from satellite imagery (USDA)
- Analyzing regulatory comments from public (EPA)
- Predicting air transportation delays (DOT)
Source Code
OMB’s M-24-10 memo clearly states in Section 4-d-i that
- Sharing and Releasing AI Code and Models: Agencies must proactively share their custom-developed code — including models and model weights — for AI applications in active use and must release and maintain that code as open source software on a public repository unless:
- the sharing of the code is restricted by law or regulation, including patent or intellectual property law, the Export Asset Regulations, the International Traffic in Arms Regulations, and Federal laws and regulations governing classified information;
- the sharing of the code would create an identifiable risk to national security, confidentiality of Government information, individual privacy, or the rights or safety of the public;
- the agency is prevented by a contractual obligation from doing so; or
- the sharing of the code would create an identifiable risk to agency mission, programs, or operations, or to the stability, security, or integrity of an agency’s systems or personnel.
Agencies should prioritize sharing custom-developed code, such as commonly used packages or functions, that has the greatest potential for re-use by other agencies or the public.
We see that only 17 of the projects had any information about source code. We presume that the remaining projects are open source, and have their source code available, and that link was not included in the provided inventory. We do not have a straightforward way of verifying this assumption.
For the 17 projects that do have their source code links in the CSV, Github links are provided, which is welcome.
Intersection with FedRAMP
One area of interest to implementers would be other federal regulations that apply to these initiatives. The most common of these would be FedRAMP, which applies to any commercial cloud based use case where federal government data is going to be stored on or otherwise transmitted into commercial public cloud systems. This would cover cloud providers such as Amazon AWS, Microsoft Azure, Google’s GCP and Oracle’s OCI and also cloud hosted applications and services such as OpenAI’s ChatGPT service.
The inventory does not provide any direct information about such specifics for any use case. We can however look at the description of the use cases and infer any cloud usage from there.
- The Department of Labor (DOL) has several projects utilizing cloud based commercial off the shelf NLP models for language translation, claims document processing and website chatbots.
- The United States Treasury has similar use cases, and is using Egain’s Intent Engine and Amazon Translate.
- The National Archives and Records Administration is using AI tools from commercial cloud providers to remove PII from records and documents that it is archiving.
- The General Services Administration is using ServiceNow Virtual Agent and OneReach AI.
- The Veterans Administration is using AiCure, a commercial application, to monitor prescription medication adherence and Medtronic’s GI Genius to aid in detection of colon polyps.
- The department of Health and Human services is using AI in several innovative ways. For example, utilizing Raisonance AI’s product that detects respiratory issues via a smartphone that analyzes the sound signature of a person’s cough, and the VisualDx app that assists physicians in visual diagnosis.
This is not an exhaustive list.
Summary
We are seeing widespread adoption of AI and Machine Learning (AI/ML) techniques across government agencies. Natural Language Processing (NLP) and Computer Vision/Neural Networks stand out as the most heavily utilized techniques. Convolutional Neural Networks (CNNs) demonstrate particular popularity in projects involving image analysis and computer vision, highlighting their effectiveness in these domains. Generative AI techniques have a small presence, but we expect that to exponentially increase.
Overall, our analysis recognizes the deep role of AI and Machine Learning within government operations. The people working in US government agencies recognize the significant benefits in terms of efficiency, data-driven insights, and enhanced decision-making processes that we have available to us from AI and machine learning, and we’re seeing evidence of that thanks to the transparency that OMBs memo M-24-10 has mandated.


