
Overview
The release of the National Institute of Standards and Technology (NIST)’s AI Risk Management Framework (AI RMF) helped put a framework around how testing would enable organizations to manage and mitigate AI risks. While testing is predominantly considered a core part of model development, the NIST AI RMF emphasizes the importance of continuous testing and monitoring of AI.
The validity and reliability for deployed AI systems are often assessed by ongoing testing or monitoring that confirms a system is performing as intended. Measurement of validity, accuracy, robustness, and reliability contribute to trustworthiness and should take into consideration that certain types of failures can cause greater harm
- NIST AI RMF §3.1
OMB’s memo M-24-10 goes into detail about the expectations around AI safety testing. Section 5c of the memo (5c. Minimum Practices for Safety-Impacting and Rights-Impacting Artificial Intelligence) has laid out the minimum practices for AI risk management. These are:
- Completing an AI impact assessment.
- Testing AI for performance in a real world context.
- Independently evaluate the AI.
- Conduct ongoing monitoring.
- Regularly evaluate the risks from the use of AI.
- Mitigate emerging risks to rights and safety.
- Ensure adequate human training and assessment.
- Provide additional human oversight, intervention, and accountability as part of decisions or actions that could result in a significant impact on rights or safety.
- Provide public notice and plain language documentation.
This white paper is part of a series that explores the approaches available to organizations for compliance with these requirements. Today, we will take a practical look at B. Testing AI for performance in a real world context.
Testing Challenges
Traditional software testing methods are insufficient for testing AI systems. The key challenges are:
1. Non-Determinism
AI models are not programmed with explicit rules. They learn from data (see 4. Explainability below), resulting in behaviors that can be hard to predict or fully control. This makes traditional “input X, get output Y” testing less reliable.
2. Lack of Clear Oracles
In traditional testing, a test oracle is a source of truth to compare the system’s output against. With AI, defining what the “correct” output is can be complex and subjective.
3. Data Dependence
AI systems are only as good as the data they are trained on. Incomplete, biased, or poor quality data leads to faulty models that perform well in testing but fail in the real world.
4. Explainability
Complex AI models, like deep neural networks, can be “black boxes.” Even when they perform well, it’s difficult to understand why they arrived at a particular decision. This limits our ability to fully test and anticipate their behavior.
5. Evolving Systems
An AI system that uses continuous learning adapts and changes over time based on new data. This makes testing a moving target, as previous test results might become outdated.
6. Computational Resource
Testing large AI models can be computationally demanding, especially recent LLMs.
Testing Strategies
No single strategy is a silver bullet. Effective AI testing often requires a combination of approaches. Lets go though some possible options that we have:
1. Non-Determinism and Adaptability
Robustness Testing: Subject the AI system to a wide range of inputs, including edge cases, noisy data, and unexpected conditions to see how it responds.
Adversarial Testing: Deliberately create inputs designed to fool the system. This helps find vulnerabilities to mitigate. Red teaming is an established practice that is being extended to this area.

2. Lack of Clear Oracles
Human-in-the-Loop: Involve human experts to evaluate AI outputs, especially in subjective areas.

Differential Testing: Use multiple AI models on the same task. If they disagree, it highlights areas needing further investigation, even if no single model is clearly “wrong.”
Uncertainty Quantification: Evaluate not just the inference, but also the measure of confidence for that inference, in order to identify when the AI is likely operating outside its area of reliability.
3. Data Dependence
Data Quality Assessment: Evaluate training data for bias, errors, and gaps.
Synthetic Data Generation: Create realistic synthetic data to test specific scenarios, especially where real-world data is limited. The use of data augmentation to artificially expand datasets for better coverage is a growing field to address this challenge.
Continuous Monitoring: Monitor live AI systems for data drift (changes in the patterns of real-world data compared to the training data), which can indicate declining performance.
4. Explainability
Explainable AI (XAI) Techniques: Use methods like Local Interpretable Model-agnostic Explanations (LIME), Shapley Additive Explanations (SHAP), or attention maps that help highlight which input features contributed most to a decision.
Sensitivity Analysis: Systematically vary input features and observe how outputs change. This can reveal the model’s reliance on specific factors.
Interpretable Models: In some cases, using simpler AI models (like decision trees) can provide inherent transparency, although often at the cost of some accuracy.
5. Evolving Systems
Model Versioning: Track changes to AI models, datasets, and code, making it possible to roll back if needed.
Regression Testing: Re-run previously established test suites on updated models to check for performance consistency.
Online Testing (A/B Testing, Canary Releases): Gradually expose new models to a small subset of real users to evaluate performance before full deployment.
Testing Frameworks – Implementation & Evaluation
Standard DevOps principles have been adapted and used in machine learning and data science projects with some success. These adaptations are grouped under MLOps. A typical
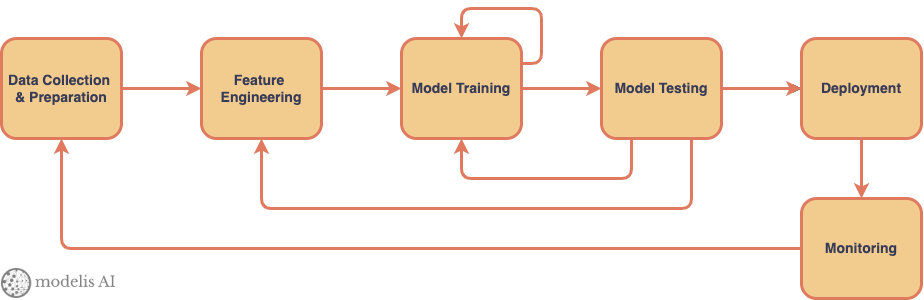
MLOps pipeline includes testing as an iterative process before deployment. As we noted above, testing AI systems has unique challenges. The strategies to address these challenges can be implemented in multiple ways. Let’s take a look at one specific example, for testing Large Language models as per the principles we’ve laid out above.
Example – Holistic Approach for LLM Testing
Scale.AI’s paper A Holistic Approach for Test and Evaluation of Large Language Models describes a robust testing methodology that applies a combination of approaches. The approaches described therein combines automated testing via deterministic evaluation, buttressed by probabilistic approaches via adversarial testing, human-in-the-loop, differential testing, and uncertainty quantification. The human-in-the loop approach innovatively applies two red teams, one consisting of domain experts in the area of the model being tested (experts), and the other group consisting of persons experienced in red team penetration testing (generalists). The objective of the approach is to achieve test coverage with a high threshold of reliability whilst managing costs via a combination of automated machine testing and human testing.
The authors innovatively used a taxonomic classification for the capabilities that the testing framework will address, and a separate taxonomy for safety evaluations (broadly categorized between risks and vulnerabilities).
The diagram below provides an overview of the testing approach.

Note: The image shown above is reproduced for readability from Scale.AI and their paper.
For the deterministic evaluation, the group used the LLM vulnerability scanner garak. Other similar tools that could be used are plexiglass, langalf or Vigil. For LLM based evaluation, this group used GPT-4 and Claude 2.0 to test Llama V2 70b Chat and Falcon 7b.
To determine uncertainty, and without the ability to directly ascertain the underlying uncertainty that an LLM might “feel” for a given answer, the authors utilized the propensity of LLMs to bias their answers depending on the order in which they were presented with choices. They used a Monte Carlo simulation to estimate confidence by repeatedly asking an LLM to compare the same two things, presented in both orders. The “entropy” of the LLM’s choices across these simulations was calculated with a lower entropy indicating that the LLMs choice is more consistent, suggesting higher confidence. Overall, this method aims to address the lack of built-in confidence scores and positional bias in LLMs, providing a way to assess how certain the LLM is about its comparisons.
Given that the research sought to introduce a hybrid approach to streamline the process of evaluating large language models (LLMs) for both capabilities and safety, we should consider the effectiveness of a method that combines rule-based and LLM-generated tests to automate parts of the evaluation process, specifically focusing on reducing the burden of human labeling.
A key aspect of this approach involves using entropy (a measure of uncertainty) in LLM preference scores. The approach identifies high-confidence cases where both LLMs strongly agree, effectively removing the need for human input in those instances. This significantly reduces the time and resources required for evaluation. The study demonstrates this efficiency by achieving near-perfect agreement with human evaluators while using only a small fraction of the total annotation time.
However, the research also acknowledges the limitations of complete automation in LLM evaluation. The study identifies two key challenges:
Self-Bias: LLMs can exhibit biases that skew their evaluation, making them unreliable for assessing their own capabilities.
Need for Human Expertise: Certain tasks, like red teaming (testing security vulnerabilities), require human judgment and creativity that cannot be fully replicated by automated methods. While the proposed method can improve red team success rates by suggesting attack strategies, it cannot replace human expertise entirely.
In conclusion, the research offers a promising hybrid approach that leverages automation to make LLM evaluation more scalable. However, it emphasizes that human oversight remains essential for the most reliable and trustworthy assessment of large language models, particularly when dealing with self-bias and complex tasks requiring human-like reasoning.
Conclusion
We have reviewed the challenges and strategies for testing AI systems, with a view to providing practical approaches towards meeting the mandate set out by OMB’s memo M-24-10. Testing AI systems is a critical part of the development and deployment process, but is challenging due to the probabilistic nature of AI models. By using a combination of testing strategies and frameworks, we can perform effective testing on LLMs and other AI systems and do so in a manner that is cost effective.
This is a fast-moving space. AI’s are becoming more complex and are being used in situations of increasing criticality, testing them becomes more important, and the complexity of how we test them scales alongside. We will continue to monitor this space and review research that attempts to address these challenges.